
In Recent past there have been lot of activity of custom chip solutions called accelerators created for Ranking/Recommendation Engines and Large Language Models (text and multi-modal) training and inference to be used in Hyper scalar data centers besides existing and established Nvidia and AMD GPU based solutions. Here I intend to discuss Meta Training Inference Accelerator-Gen5 Olympus and Trainium2 from Amazon solutions primarily created for Cloud servers for Text and Multi-Modal based AI servers with its Features and Architecture and finally Ironwood from Google flagship TPU. This gives an idea about compute, memory, IO and networking subsystems evolution for underlying platform.
Meta Training and Inference Solution called Olympus:(Looks primarily inference part based on specifications)
| Source:ai.meta.com | Claims 3x Perf improvement over First Gen |
| Primary Use Case: Ranking and Recommendation Engine (looks more like inference engine for all practical purposes) | 4 Models used to evaluate: Low Complexity and High Complexity Ranking and Recommendation Models and Advertisement’s ranking model |
| Compute Capabilities | GEMM Dense Compute: 3.5x improvement, GEMM Sparse Compute:7x improvement (int8 708/BF16 354 TFLOPS/s), Dense Compute (int8 354/BF16 177 Tflops/s), SIMD 5.53 TFLOPS/s(int8, BF16) |
| Memory Capacity | 256MB on-chip and LPDDR5 for off-chip planned up to 128GB |
| Memory Bandwidth | 204.8 GB/s offchip,2.7 TB/s Onchip,1TB/s/PE |
| Connectivity betn Accelerators and Host to/from accelerators | PCIe-Gen5 |
| Scale Out Connectivity | RDMA w/NIC (claims 6x Model serving throughput over first Gen w/2x number of devices supported) |
| Software Customized Tool Chain | Pytorch 2.0 and runtime includes Triton Compiler/Graph Compiler |
| Technology/Die Area | 5nm @ 1.35Ghz/421 sq mm |
| Topology of Engines/Part | Grid of 8×8 Processing elements each with 384KB of SRAM |
| Thermal Design Power | 90 Watts |
| Memory Bandwidth | 204.8 GB/s offchip,2.7 TB/s Onchip,1TB/s/PE |
| Network On Chip protocol | Unknown/Not disclosed but inspired by systolic array and connected in mesh topology with some Routing heuristic similar to Dimensional routing to minimize Hop latency |
Based on all published data there seems to be no hardware coherency supported between engines connected on 8×8 grid, therefore the 384KB sram with each processing element is kept coherent with software help. Since RDMA support is added along with NIC connectivity, solution seems to support datacenter-based clusters created using Racks containing such parts. Triton Backend compiler support in software tool chain seems to make GPU like programming hardware agnostic. There is extensive support of telemetry borrowed from Nvidia GPU cluster experience and not discussed here but sufficient to give visibility of utilization and stalls at various level of functional hierarchy. In rack-based system holds up to 72 accelerators consisting of three chassis, each containing 12 boards that house two accelerators each. There is a mention that to clock the chip at 1.35GHz and run it at 90 watts compared to 25 watts for first-generation design.
On training side, Amazon Trainium2 and Trainium3 might be another interesting part since it is offered as alternative to Nvidia GPUs by AWS, I captured from their site features and architecture of trainium2, here are some features captured for Trainium2, Trainium3(besides it is 3nm part and 40% performance improvement over Trainium2) information in public domain is incomplete as of now:
| Source: https://awsdocs-neuron.readthedocs-hosted.com/ | Claims 6.7x improvement (Flops/s over Tranium1 w/FP8 and 3.7x for BF16 data types) |
| Primary Use Case | Trainium2 optimized for LLM/Diffusion models whereas Tranium3 optimized for multi-model distributed training |
| Technology | 7nm for Trainium2 and 3nm for Trainium3 |
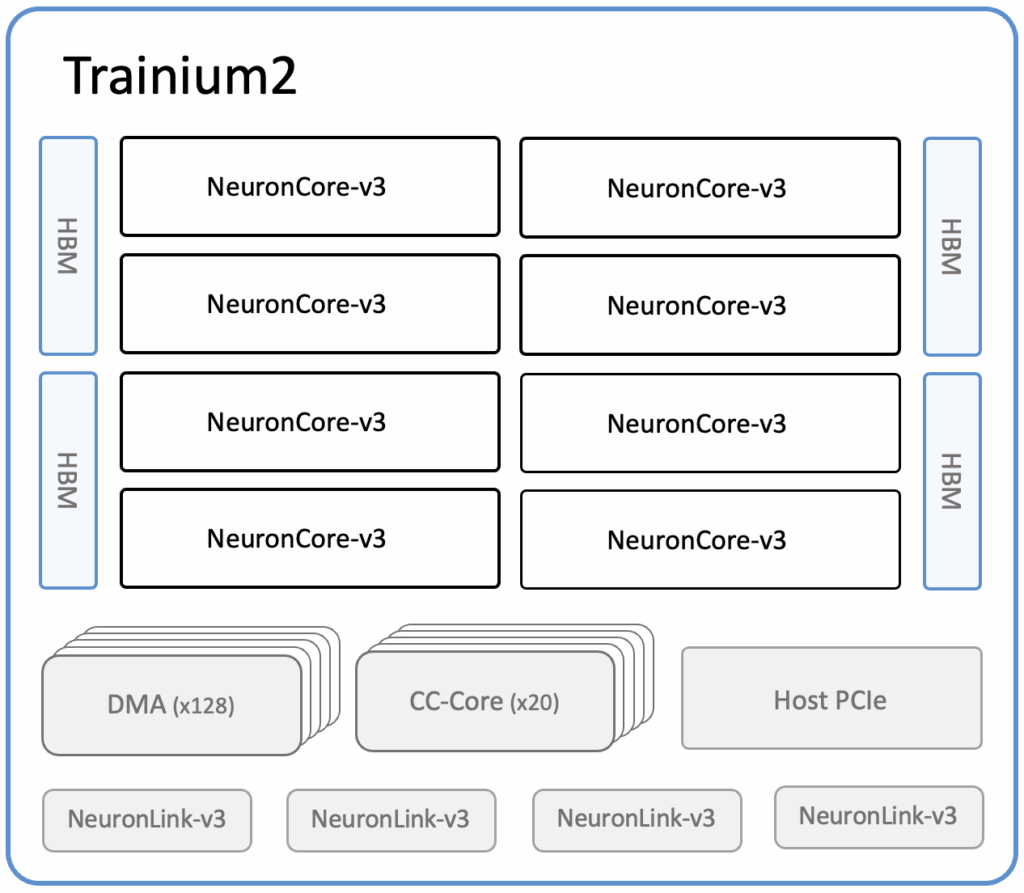
| Processing Elements | 8x NeuronCore-v3 engines /part, Trainium2 supports dynamic shapes and control flow via NeuronCore-v3 ISA extensions, supports 20 special cores with support for collective communication library |
| Compute | 1299(FP8 TFlops/s),667 (BF16 TFLOPS/s) |
| Memory | 224 MB internal SRAM memory,96GiB HBM3 support, DDR support not published |
| Connectivity w/NeuronLink-v3 | Supports 3.5TB/s DMA bandwidth w/inline compression/de-compression support as well as supports DMA barriers. Supports 1.28 TB/sec scale up/out bandwidth per chip. |
| Memory Bandwidth to HBM3 | 2.9TB/sec |
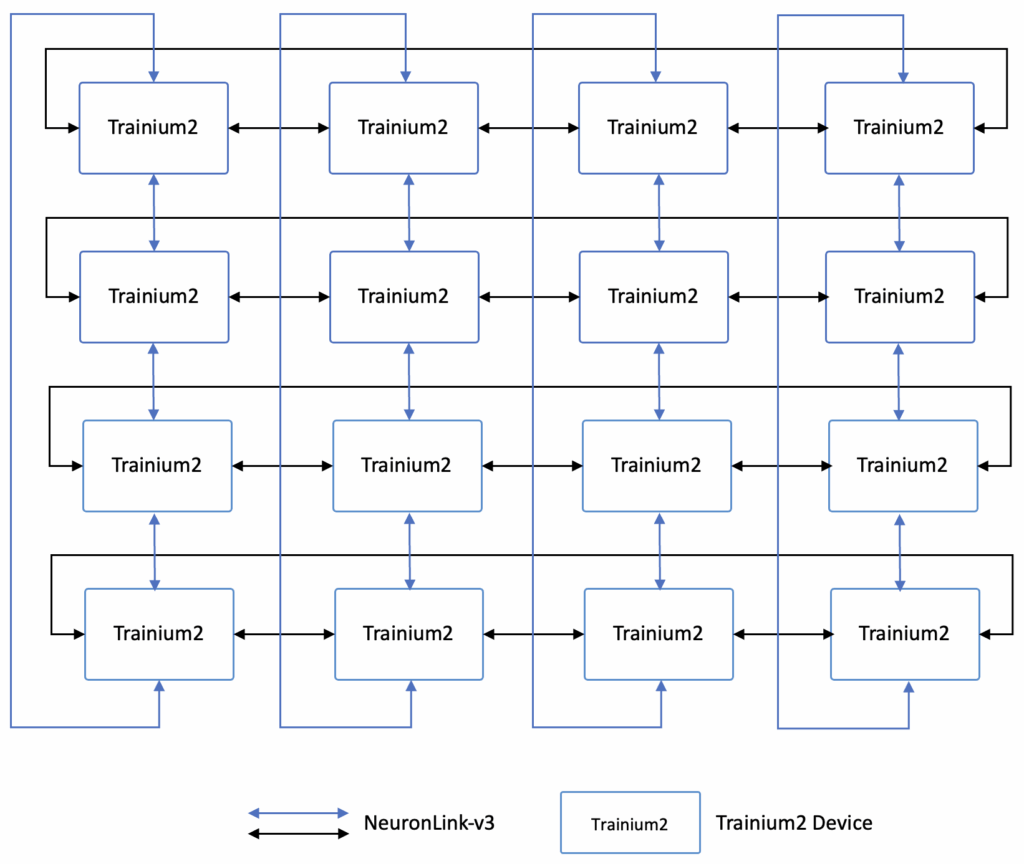
| Scale Up Topology | NeuronLink-v3 2D/3D Torus supports 2D(4×4) and 3D(4x4x4) |
| TDP/Die Area/ Operating Voltage | Not Available |
| Data Movement | Supported by 20 special cores called CC cores which supports DMA barriers between external memory and internal SRAM |
| Software Tool Chain seems to be designed for Neuron Core | Pytorch Neuron, JAX Neuron, TensorFlow Neuron supported with special Neuron libraries for Transformer and training/Inference. |
| NOC topology | Not disclosed |
Power Profile is missing and possibly though a claim has been made that trainium3 is 40% more energy efficient than trainium2 that is important to know. AWS hosts many different LLM vendors and thus have access to their workload running profiles which would be useful for future optimizations in trainium3 onwards, a clear advantage.
Google Ironwood Tensor Processing Unit is the last solution in this post which might be interesting to look at from capabilities perspective. Ironwood promises to handle the computational and memory demands of models such as Large Language Models (LLMs), Mixture-of-Experts (MoEs), and advanced reasoning tasks supporting both training and serving workloads within the Google Cloud AI Hypercomputer architecture. Based on published metrics it definitely looks very powerful and most of comparisons are w.r.t H100:
| Source: https://cloud.google.com/ | 2x of Trillium (TPU v2), with PODs configuration offers performance in Exaflops (e.g:42.5) |
| Primary Use Case | As per documentation not meant for vision and scientific simulations but good for LLM(both dense and sparse)-inference and training(limited), Recommendation Engines. Applications supported Gemini, Alphafold, Translate, Seach and Advertisement |
| Software Toolchain | Tensorflow, JAX, XLA |
| Compute | Mainly Systolic Array design, published Exaflop (~42.5) level performance for TPU Pod. Compute per chip is ~4614 Tflops/s and Optimized for Matrix Multiplication and Tensor operations. |
| Memory | 192 GB HBMx memory |
| Memory Bandwidth | 7.2TBps from HBM memory |
| Interconnect – Scale up Connectivity within TPU Pod | Connects up to 9216 TPU’s with ICI link and 1.2Tbps link bandwidth |
| Thermal | Needs Liquid Cooling |
| Energy Efficiency | 2x of previous generation |
| Programmability (Low) | Primarily used within Google Cloud |
Although last part seems powerful, but from usability point of view google cloud is now the only option to use it. Also internal details are scant and thermal might be cost adder since it needs advance cooling solutions.
I will go workload mapping and architectural deep dive in future blogs of these parts but above gives idea where the infrastructure development with hyper scalars is moving. I will leave the judgement of these parts to reader, but clearly part needs to be cost effective and thermally manageable.